Work Hours
Monday to Friday: 10.00 - 19.00

Executive Summary
Part 2: Turning AI FinOps from theory into measurable results
Part 1 established a hard truth: 28% of cloud spend is still wasted, even among fast-scaling startups. In 2026, this waste is no longer caused by missing tools, it’s driven by decision lag.
Static dashboards, monthly reviews, and manual controls cannot keep pace with AI-driven workloads, GPU volatility, and usage-based pricing.
AI-powered FinOps changes the equation, not by blindly automating decisions, but by enabling cost governance that keeps pace with AI workloads.
It transforms cost management from reactive cleanup into a continuous, predictive operating model, one that governs AI spend at machine speed while preserving engineering velocity and decision accountability.
This guide delivers:
- A four-phase AI FinOps roadmap used by high-performing startups
- A 60-day execution playbook designed for early wins without slowing delivery
- Practical guidance on forecasting, autonomous optimisation, and real-time control
- A proven case showing ~50% AI spend reduction, <5% budget variance, and 1.5-month payback
- A single AI FinOps Action Pack to accelerate execution
Outcome-driven focus:
Teams that follow this roadmap typically unlock 25–35% cloud savings over a 12-month maturity horizon, while gaining the predictability investors expect and the trust engineers require.
This is not about cutting costs.
It is about governing AI spend deliberately, so growth remains intentional, predictable, and scalable.
This guide is supported by a downloadable AI FinOps Action Pack, which distils the four-phase roadmap, 60-day execution checklist, strategic alignment scoring framework, and key AI cost metrics used throughout this article into practical, executive-ready tools.
Part 1 recap: Why AI FinOps became non-negotiable
Part 1 showed why traditional FinOps breaks down in the AI era.
Modern cloud spend is no longer linear, predictable, or human-readable. It is shaped by:
- AI inference that scales by the minute
- GPU pricing that fluctuates daily
- Token-based billing that compounds invisibly
- Teams shipping faster than finance can review
The result is cost volatility without clear accountability.
AI-driven FinOps for AI workloads emerged not as an innovation trend, but as a structural requirement. Part 1 outlined five core capabilities that enable this shift:
- Predictive forecasting based on live usage signals
- Real-time anomaly detection before invoices arrive
- Autonomous rightsizing across compute, GPUs, and inference pipelines
- Intelligent purchasing without manual scenario modelling
- Context-aware optimisation balancing cost, performance, and compliance
Together, these capabilities allow FinOps to operate as a living system, not a reporting function.
However, understanding why AI FinOps matters is only half the equation.
Execution is the real challenge.
That is where this guide, and the execution framework that follows, begins.
The 4-phase AI FinOps roadmap
High-performing startups adopt AI FinOps as a maturity progression, not a one-time optimisation exercise. Visibility becomes prediction, prediction becomes automation, and automation becomes an operating loop.
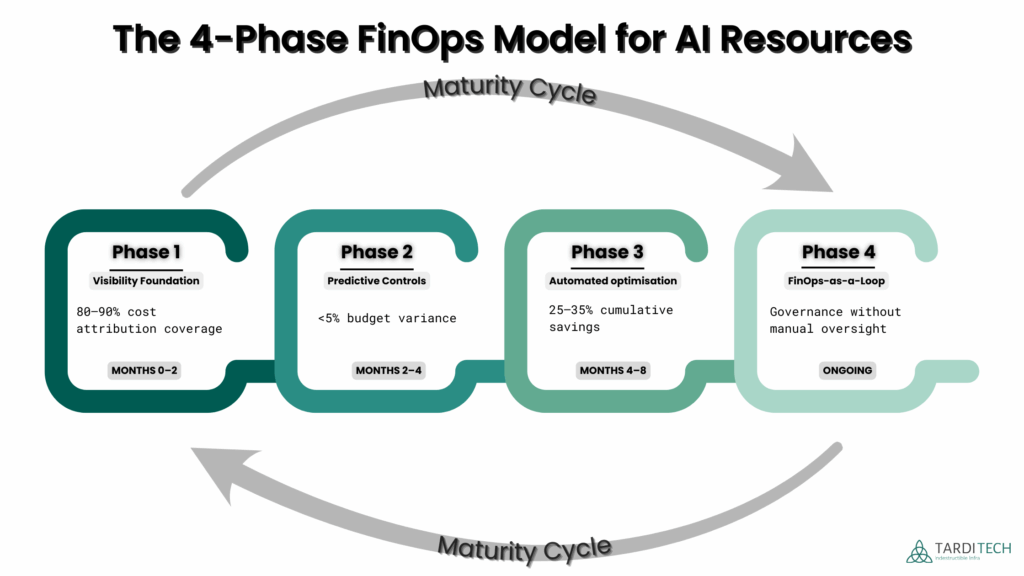
This four-phase roadmap reflects how AI-driven FinOps is implemented in 2026. Each phase builds on the previous one, delivering measurable gains without disrupting engineering velocity.
Phase 1: Visibility foundation
Establish clear cost attribution and ownership across AI workloads, including GPUs, inference endpoints, and token consumption.
Typical impact: immediate waste exposure and accountability.
Phase 2: Predictive controls
Move from reporting to forecasting using live usage signals and anomaly detection, preventing cost surprises before they reach invoices.
Typical impact: <5% budget variance and restored planning confidence.
Phase 3: Automated optimisation
Enable continuous rightsizing, scheduling, and intelligent routing within defined guardrails, reducing waste at machine speed.
Typical impact: 25–35% cumulative savings.
Phase 4: FinOps-as-a-loop
Embed FinOps into day-to-day operations through intent-based policies that scale governance automatically as usage grows.
Typical impact: sustained efficiency without manual oversight.
Why sequencing matters
High-performing startups adopt AI FinOps as a maturity progression, not a one-time optimisation exercise. Visibility becomes prediction, prediction becomes automation, and automation becomes an operating loop.
📘 The full roadmap, phase details, ownership model, and execution guidance are included in the AI FinOps Action Pack.
The 60-day AI FinOps execution playbook
The roadmap defines where teams are heading.
The 60-day playbook defines how teams begin safely, incrementally, and without overwhelming engineering or finance.
Weeks 1–2: Establish cost ownership
The first priority is visibility and accountability. Most early waste comes from unowned AI spend, not overuse.
Teams focus on:
- Making AI, GPU, and token spend visible by workload
- Establishing clear technical and financial ownership
- Exposing low-risk, immediately addressable waste
Outcome: Cost conversations become factual and actionable rather than reactive.
Weeks 3–4: Move from reporting to prediction
Once ownership exists, teams shift from explaining past spend to controlling future outcomes.
This phase introduces:
- Forecasting based on live usage signals
- Early anomaly detection before invoices land
- Cost alerts routed to operational teams, not just finance
Outcome: Budget variance drops, and leadership regains confidence in forward-looking decisions.
Weeks 5–6: Activate automated optimisation
With visibility and prediction in place, automation becomes safe.
Teams begin:
- Continuous rightsizing and scheduling
- Intelligent routing for eligible AI workloads
- Reducing manual intervention in cost tuning
Outcome: The majority of early savings are unlocked without performance regressions.
Weeks 7–8: Close the leadership loop
The final phase formalises how cost intelligence feeds decision-making, not just optimisation.
Teams establish:
- Guardrails instead of manual approvals
- Scenario modelling for commitments and budgets
- Clear accountability without micromanagement
Outcome: FinOps shifts from cost control to operational governance.
Why this sequencing works
Teams that automate before forecasting stall.
Teams that overanalyse never ship.
This 60-day sequence balances speed and safety:
- Visibility first
- Prediction second
- Automation third
- Governance last
Each step compounds the next, delivering control without organisational fatigue.
📘 The full 8-week execution checklist, owners, success signals, and sequencing details are included in the AI FinOps Action Pack.
AI cost-control strategies that actually move the needle
Once visibility, predictive controls, and guardrails are in place, cost optimisation becomes a question of where governed leverage exists, not how aggressively to cut.
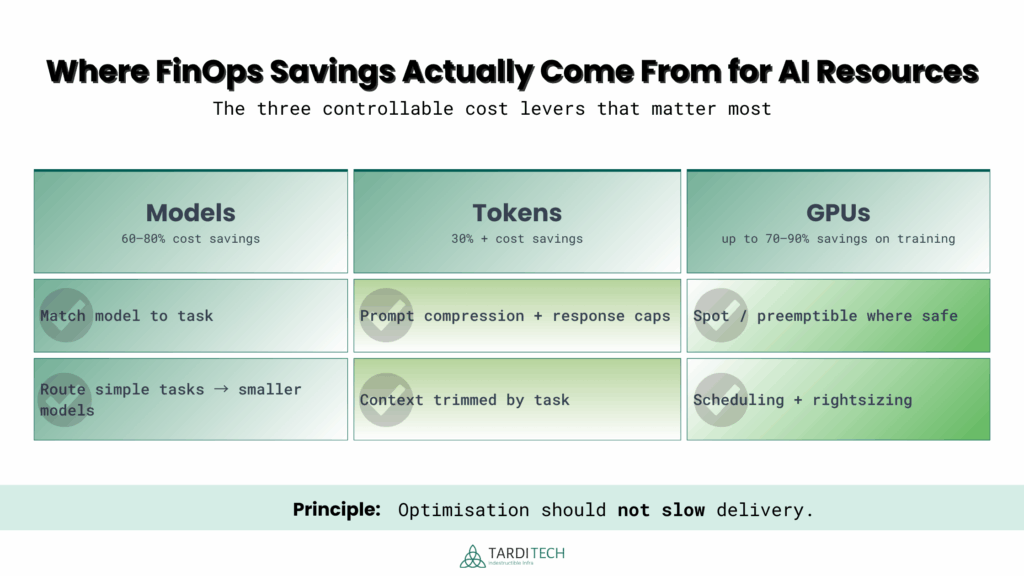
In AI-heavy environments, governed optimisation consistently concentrates in three areas:
- Model selection
- Token efficiency
- GPU utilisation
This is where most AI FinOps savings are realised and where undisciplined decisions quietly erode margins.
Model selection: matching intelligence to economic value
Not every workload requires frontier intelligence. Yet many teams default to the most capable model by habit rather than necessity.
High-performing teams apply model–task alignment:
- Lower-cost models for classification, summarisation, routing, and extraction
- Larger models reserved for complex reasoning or customer-facing outputs
- Dynamic routing based on task complexity
Why this matters:
Model choice alone can create 60–80% cost variance for identical outcomes. Paying for unnecessary reasoning depth is one of the fastest ways AI spend balloons without ROI.
This is enforced through policy-based routing and reviewable rules, not ad-hoc engineer decisions.
Token efficiency: controlling the invisible multiplier
Tokens scale silently. Small prompt changes can double inference costs without triggering alerts.
Disciplined teams introduce:
- Prompt compression and structured outputs
- Hard limits on context and response length
- Dynamic rules based on task type
Typical impact:
30%+ reduction in token consumption with no degradation in output quality.
Why this matters:
Inference costs scale linearly with usage. Without token governance, margins decay as adoption grows.
Token controls are defined centrally but applied automatically at runtime.
GPU optimisation: where big wins - and big risks - live
GPUs are the largest and most volatile cost driver in AI stacks. The difference between disciplined and reactive teams is orchestration, not usage.
High-impact levers include:
- Rightsizing over-provisioned instances
- Enforced shutdown schedules for non-production workloads
- Selective use of spot or preemptible capacity
- Separating training and inference architectures
Typical impact:
Up to 70–90% savings on eligible training workloads and 60%+ idle reduction outside production hours.
Why this matters:
GPU costs don’t just spike, they compound. Manual controls fail at scale.
Cost control without bottlenecks
These strategies work because they respect a core FinOps principle:
Optimisation should not slow delivery.
When model choice, token limits, and GPU scheduling are automated and policy-driven:
- Engineers stop firefighting cloud bills
- Finance gains predictability without blocking experimentation
- Leadership controls margins without operational drag
This is the difference between cutting costs and governing costs.
📘 Detailed benchmarks, tactics, and decision rules are included in the AI FinOps Action Pack cheatsheet.
Strategic alignment framework: prioritising what actually moves the needle
Once visibility, predictive controls, and automation are in place, teams face a new challenge: there are many possible optimisation opportunities, but not all of them deserve attention at the same time.
This is where AI FinOps shifts from optimisation to decision discipline.
High-performing startups do not chase every potential saving.
They apply a simple alignment framework to ensure cost initiatives support growth, reliability, and delivery speed- not just lower invoices.
From data to decisions in a changing landscape
AI-driven environments generate constant optimisation signals:
model routing, token limits, GPU scheduling, commitment purchases.
At the same time, the decision surface is expanding.
By 2026, AI FinOps operates in a materially different context:
- Cost governance increasingly happens through intent-based policies, not dashboards
- Predictive optimisation surfaces impact before deployments and architecture changes
- Cost visibility extends beyond infrastructure into tokens, APIs, SaaS, and GPU lifecycles
- Automation becomes the default execution layer, not a one-off optimisation tactic
This creates both opportunity and risk.
Without structure, teams oscillate between analysis paralysis and reactive cost-cutting.
With structure, optimisation becomes strategic and repeatable.
The question this framework answers is simple:
Which FinOps actions deliver the highest business impact with the least operational risk?
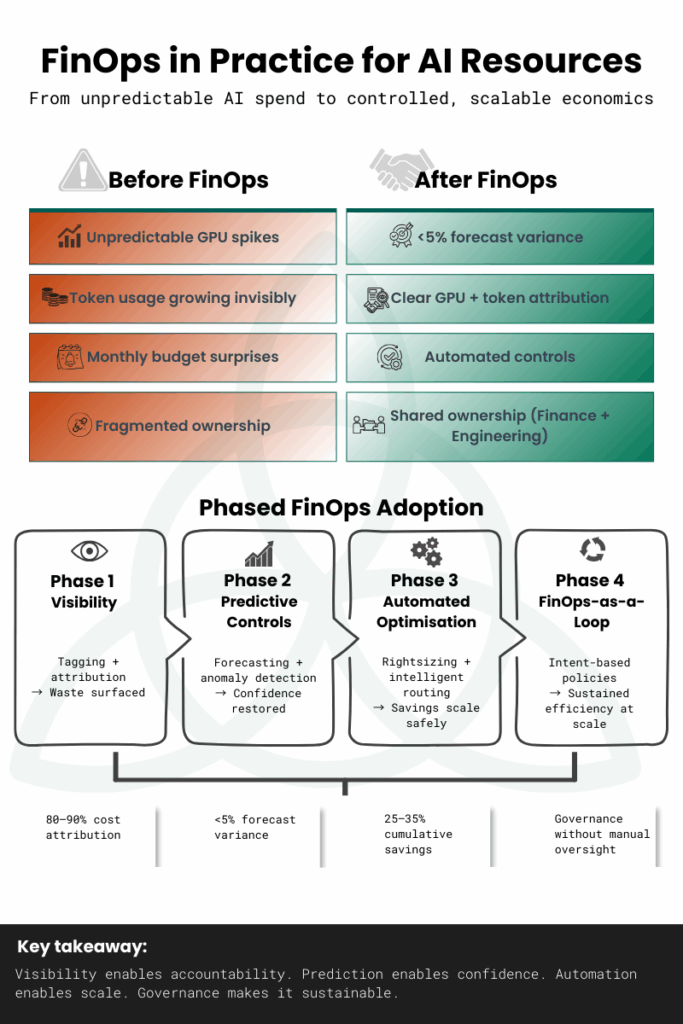
This visual shows how AI FinOps decisions flow across finance, engineering, and leadership, highlighting why structured prioritisation is required before optimisation is applied.
The 4-factor decision lens
Each optimisation initiative is evaluated across four dimensions to support clear, shared prioritisation across leadership, finance, and engineering:
- Business impact
Effect on revenue protection, growth, or customer experience - Savings potential
Realistic percentage or absolute cost reduction - Ease of implementation
Engineering effort, tooling changes, and coordination required - Safety and reversibility
Likelihood of performance degradation or delivery disruption
Each factor is scored on a simple 1–3 scale (low, medium, high).
The combined score helps teams decide what to execute now, what to sequence next, and what to defer, without relying on gut feel or urgency.
This framework does not replace engineering judgment.
It aligns it, giving finance, engineering, and leadership a shared language for making deliberate trade-offs.
Why this works in practice
Used consistently, this framework changes behaviour:
- Teams stop over-optimising low-impact areas
- Quick wins surface before risky infrastructure changes
- Cost decisions move into leadership discussions, not spreadsheets
For example, GPU spot migration may offer the largest raw savings, but token optimisation or model routing often delivers faster, safer returns early on. Mature teams sequence accordingly.
This sequencing matters even more in 2026, because execution still breaks in familiar ways:
- Poor data quality undermines trust in recommendations
- Over-automation before forecasting maturity creates regressions
- FinOps framed as a finance constraint triggers resistance
- Unclear ownership stalls AI cost decisions
The alignment framework exists because of these realities.
It ensures teams make deliberate trade-offs instead of reactive cuts.
Key performance metrics to track
AI-driven FinOps only works if teams agree on what “good” looks like.
In 2026, high-performing startups track a small, focused set of metrics that balance cost discipline with delivery speed. These metrics give leadership confidence without pulling engineers back into spreadsheets.
The goal is not to track everything, it is to track what influences decisions and behaviour.
Financial metrics: predictability and runway
These metrics answer one core question:
Are we spending in line with growth and intent?
- Budget variance (target: <5% month over month)
Confirms forecasting accuracy and reduces end-of-month surprises. - Wasted spend percentage (target: <10%)
Indicates maturity of tagging, ownership, and automated cleanup. - Cost per customer / cost per feature
Connects AI and cloud spend directly to business outcomes. - Commitment coverage (target: >70% on steady workloads)
Balances savings with flexibility as usage evolves.
Why this matters:
Finance gains predictability, leadership protects runway, and growth decisions stop being made blindly.
Operational metrics: speed and control
These metrics show whether FinOps is enabling teams or slowing them down.
- Forecast accuracy (target: ~90%)
Signals predictive controls reflect real usage patterns. - Anomaly detection time (target: <10 minutes)
Measures how quickly unexpected spend is identified and contained. - Optimisation adoption rate
Percentage of AI-recommended actions applied, signalling trust in the system. - Engineering time spent on cost reviews (target: trending down)
Confirms automation is removing manual burden.
Why this matters:
Cost governance should reduce operational friction, not create new process overhead.
AI-specific metrics: where costs actually hide
AI workloads introduce cost dynamics that traditional cloud metrics miss.
- GPU utilisation rate (target: >60–70% sustained)
Highlights idle capacity and scheduling inefficiencies. - Token cost per output
Reveals inefficiencies in prompt design, context usage, and model selection. - Cost per inference / per AI feature
Enables true unit economics for AI-driven products. - Training vs inference spend ratio
Prevents experimentation from silently dominating production budgets.
Why this matters:
AI costs scale non-linearly. Without AI-specific metrics, leaders lose control precisely where adoption accelerates.
A principle for metric discipline
High-performing teams track fewer metrics, reviewed more often, with clear ownership.
If a metric does not influence a decision, prioritisation, or behaviour, it does not belong in the dashboard.
The AI FinOps action pack: everything you need to execute
AI FinOps only delivers value when strategy turns into execution.
That’s why this guide is paired with a single, focused AI FinOps Action Pack, designed for CTOs, CFOs, and founders who want results without stitching together frameworks, spreadsheets, and tools.
The pack distils this guide into practical, reusable assets teams can apply immediately.
What’s included
- 4-phase AI FinOps roadmap
A visual roadmap showing phase transitions, ownership shifts, and measurable outcomes across finance, engineering, and leadership. - 60-day execution checklist
A week-by-week playbook aligned to the roadmap, designed for fast wins without slowing delivery. - AI cost optimisation cheatsheet
Benchmarks and tactics for model selection, token efficiency, and GPU optimisation — all in one reference. - Strategic alignment scoring template
A simple 4-factor decision lens teams can use in leadership reviews to prioritise initiatives confidently. - Key metrics tracking matrix
Financial, operational, and AI-specific KPIs mapped to owners, targets, and review cadence. - FinOps maturity snapshot
A one-page view to assess where your organisation sits today and what “good” looks like next. - Readiness checklist
A short diagnostic to identify gaps before scaling AI usage further.
All assets are executive-friendly, lightweight, and immediately usable, not long PDFs that never leave a folder
Final Thought: FinOps as a Growth Capability
In 2026, FinOps is no longer a cost-cutting exercise.
It is a strategic capability that determines how confidently a startup can scale. Teams that adopt AI-driven FinOps early gain more than savings: they gain predictability, faster decision-making, and the freedom to innovate without financial surprises.
As the FinOps Foundation defines it, FinOps is ultimately about enabling teams to make better, faster decisions with shared accountability.
The difference is not tooling.
It’s discipline, alignment, and execution.
Take the Next Step
📥 Download the AI FinOps Action Pack
Everything in this guide, distilled into practical tools for governing AI spend with confidence.
📞 Book a Free Strategy Call with TardiTech
No sales pitch. Just a practical conversation about your current setup, risks, and next best moves.
AI FinOps works best when it’s embedded early and built deliberately.